
OSTEP虚拟化CPU
第四章 进程
进程是运行中的程序,程序是磁盘上的指令——操作系统让程序运行
核心观点:进程是状态机 知道当前状态以及下一状态就可以执行
小点总结:
- 想要为每一个进程提供CPU
- 如何实现进程切换 进程切换带来内存损失
- 进程的机器状态——程序在运行时可以读取和更新的内容
- 进程API有哪些?
- 如何创建进程
- 进程有哪些状态
- 操作系统是一个程序,和其他程序一样,它有一些关键的数据结构来跟踪各种相关的信息。
问题1:想要为每一个进程提供CPU
解决方案:虚拟化CPU——时分共享CPU
- 一个进程运行一个时间片 然后切换到其他进程
问题2:如何实现进程切换 进程切换带来内存损失
- 机制决定了进程切换可实行,例如上下文切换
- 策略来调动机制减小内存损失
问题3:进程的机器状态——程序在运行时可以读取和更新的内容
- 内存(地址空间):
- 指令
- 程序读取和写入的数据
- 寄存器:
- 程序计数器
- 栈指针
- 帧指针
问题4:进程API有哪些?
创建进程、销毁进程、等待进程、暂停进程、恢复进程、读进程状态
问题5:如何创建进程
- 读取程序字节到内存中
- 为栈分配内存——局部变量、函数参数和返回地址
- 为堆分配内存——malloc free分配
- 初始化三个文件描述符标准输入、标准输出、标准错误
- 启动程序——main(start)
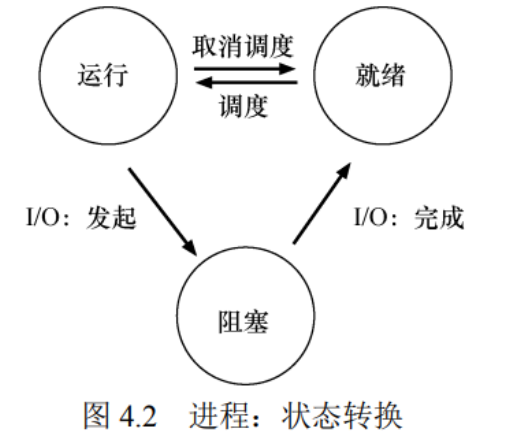
问题6:进程有哪些状态
- 运行
- 就绪,操作系统选择不在此时执行
- 阻塞,进程自己IO时阻塞,不使用CPU
问题7:操作系统是一个程序,和其他程序一样,它有一些关键的数据结构来跟踪各种相关的信息。
- 进程停止时将进程信息保存到内存中 随后操作系统可以在该地址重启该进程
xv6内核中每个进程的信息类型
1 | // the registers xv6 will save and restore |
第五章 进程API
1 fork()系统调用
1 | int fork(); // 创建一个进程 返回子进程的PID |
- 父进程和子进程具有相同的资源(寄存器值、内存数据、指令)
- 只有
fork()的返回值不同,父进程返回子进程的pid,子进程返回0
2 wait()系统调用
1 | int wait(int *status); // 等待一个子进程退出 将退出状态存入*status 返回子进程PID |
- 父进程调用
wait(),那么wait()后的指令会等待子进程结束后才运行(如果有子进程的话)
3 exec()系统调用
1 | int exec(char *file, char *argv[]); // 加载一个文件并使用参数执行它 只有在出错时才返回 |
4 fork() 和 exec() 分离可以有助于实现IO重定向等操作
第六章 机制:受限直接执行
受限直接执行是CPU虚拟化的底层机制
小点总结:
- 什么是直接执行?
- 用户模式和内核模式
- 陷阱指令和从陷阱返回指令
- 为什么系统调用看起来像过程调用?
- 陷阱如何知道OS内运行哪些代码?
- 受限直接执行
- 如何让操作系统获得控制权?
- 操作系统要切换进程——上下文切换
- 并发问题怎么解决?
虚拟化CPU的基本思想:时分共享CPU - 性能问题:进程高效运行
- 控制权:OS对CPU的控制
本章两大问题: - 如何在不增加系统开销的情况下实现虚拟化?
- 如何有效地运行进程,同时保留对CPU的控制?
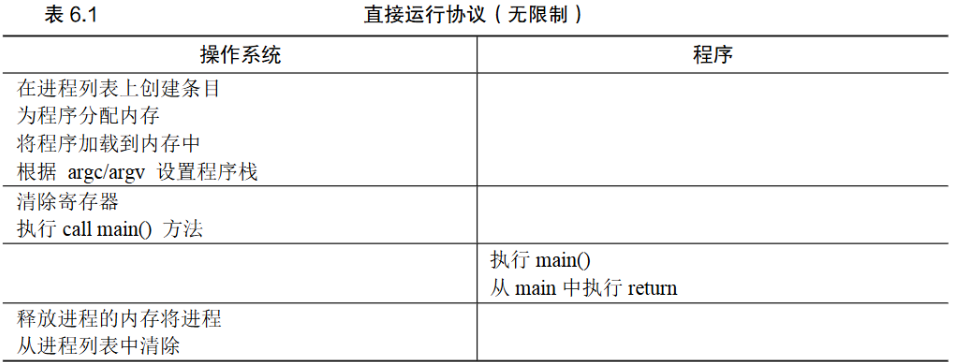
1 什么是直接执行?
- 操作系统保存当前的状态后,直接跳转到需要执行的程序执行
- 随后返回内核
- 程序直接在CPU硬件上执行——快
此方法存在的问题:操作系统无法控制程序 - 无法确保程序只做规定的事情
- 不能实现时分共享
2 用户模式和内核模式
- 硬件提供用户模式和内核模式
- 用户模式下不能完全访问硬件资源
- 内核模式下操作系统可以访问机器全部资源
3 陷阱指令和从陷阱返回指令
- 程序执行陷阱指令,在陷入内核之前,保存好当前状态等待之后的恢复(寄存器放到内核栈),将特权级别设为内核模式
- 系统执行相关指令之后,从陷阱返回,返回用户进程并将特权级别降为用户模式
4 为什么系统调用看起来像过程调用?
open等指令在外观上是过程调用,但是其内部实现是汇编,有陷阱指令
5 陷阱如何知道OS内运行哪些代码?
- 进程发起陷阱指令,但是不知道陷阱指令之后具体跳转到内核的哪一步
- 操作系统内核在启动时设置了陷阱表,记住系统调用处理程序的位置
6 受限直接执行
- 用户模式和内核模式的分离,陷阱指令补充用户模式的操作限制
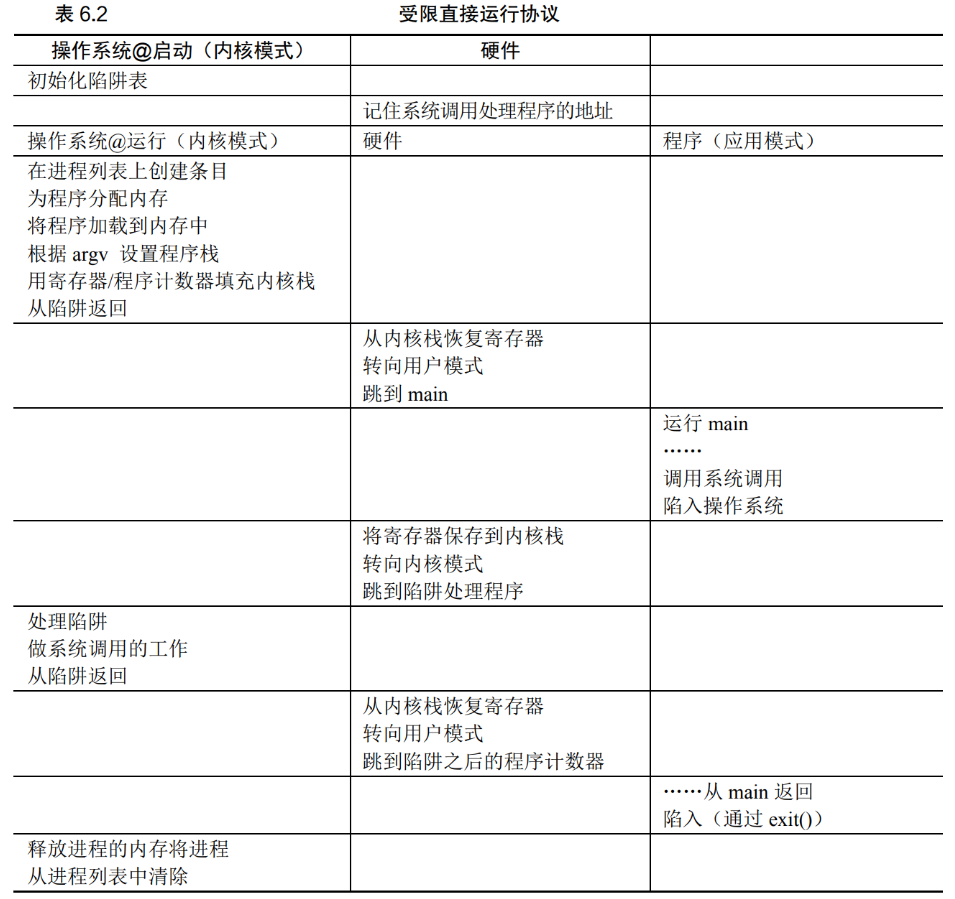
7 如何让操作系统获得控制权?
- 进程在CPU上运行时,操作系统没有运行
7.1 协作方式:等待系统调用
OS通过等待系统调用,或某种非法操作发生,从而重新获得CPU的控制权
如果进程不进行系统调用,则操作系统无法重新获得控制权,只有重新启动计算机
7.2 非协作方式:操作系统进行控制
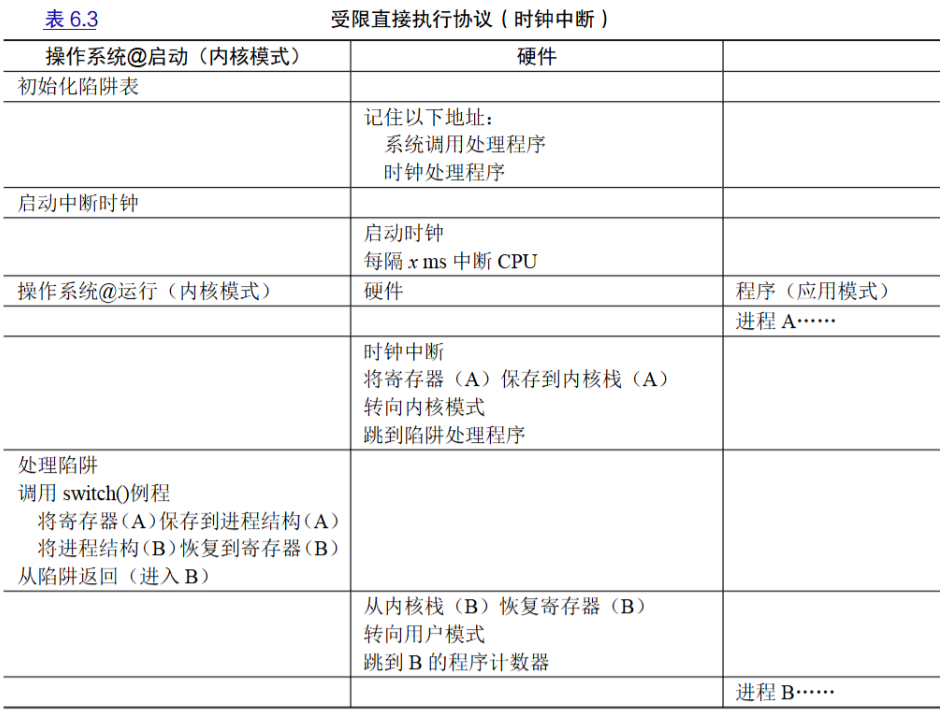
利用时钟中断获得重新控制权
时钟设备可以编程为每隔几毫秒产生一次中断,在中断处理程序中,让操作系统重新获得CPU的控制权
8 中断发生后要为当前进程保存足够状态,保存到内核栈
9 操作系统要切换进程——上下文切换
- 先保存该进程的寄存器的值到进程结构
- 恢复即将执行的进程的寄存器的值
- 从trap返回到用户模式,执行新的进程
xv6的上下文切换代码
1 | # void swtch(struct context **old, struct context *new); |
10 并发问题怎么解决?
- 中断处理期间禁止中断
- 加锁(locking)
第七章 进程调度:介绍
进程调度是CPU虚拟化的高级智能
本章核心问题:如何开发调度策略?评价策略好坏的指标?
小点总结:
- 工作负载假设
- 调度指标:周转时间
- 策略1:先进先出FIFO
- 策略2:最短任务优先SJF
- 非抢占式调度与抢占式调度
- 策略3:最短完成时间优先STCF
- 新调度指标:响应时间——交互性评价
- 策略4:轮转
- 策略5:结合I/O
- 操作系统无法预知进程的工作时间
1 工作负载假设
以下假设将被逐步剔除(先做出如下假设可以简化理解)
- 每一个进程运行相同的时间
- 所有的进程同时到达
- 一旦开始,每个进程保持运行直到完成
- 所有的进程只是用CPU(即它们不执行IO操作)
- 每个进程的运行时间是已知的
2 调度指标:周转时间
- 任务完成时间减去任务到达系统时间——性能指标
$$T_{周转时间} = T_{完成时间}-T_{到达时间}$$
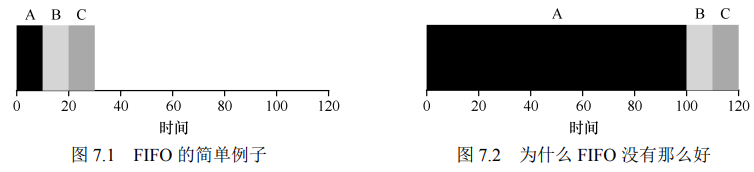
3 策略1:先进先出FIFO
- 先到达系统的进程先运行
ABC三个任务依次到达(时间几乎相同)
先进先出导致会出现平均周转时间过大的情况,如下右图
4 策略2:最短任务优先SJF
- 在考虑所有任务同时到达时,SJF是一个好的策略
若出现A先到达,BC随后到达,还会出现平均周转时间过大的情况(不考虑程序进程切换)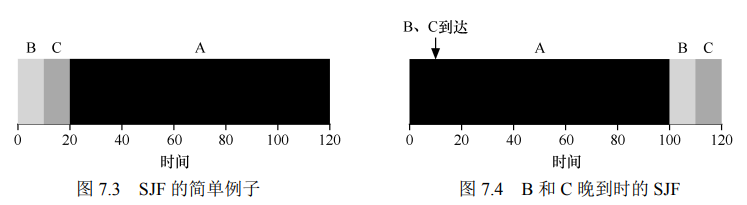
5 非抢占式调度与抢占式调度
- 非抢占式调度:每次进程开始就一直工作完才考虑下一步的调度,上述FIFO、SJF
- 抢占式调度:可以进行上下文切换的调度,下述STCF
6 策略3:最短完成时间优先STCF
- 当有新进程进入系统,确定剩余进程和新进程的剩余时间,选择剩余时间最少的先执行
该策略可以有效减少平均周转时间,但是会出现用户等待系统响应时间过长的情况(即由于进程需要时间较长,总是等到最后才运行,用户需等待很久才能看到该进程的响应)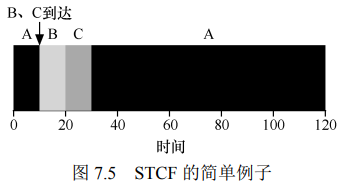
7 新调度指标:响应时间——交互性评价
- 从任务到达系统到首次运行的时间
$$T_{响应时间} = T_{首次运行}-T_{到达时间}$$
8 策略4:轮转
- 时间切片,任务按照时间片轮流执行
- 以减少响应时间为目标
- 周转时间显著增加了
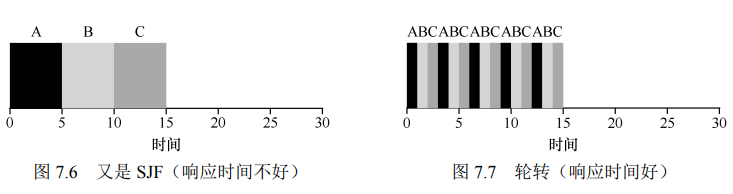
这种方法需要较为频繁上下文切换,时间片长一点可以摊销上下文切换的成本
9 策略5:结合I/O
- 正在进行的作业在I/O时会被阻塞,此时应该要安排其他的作业使用CPU
- 所有程序都执行I/O,否则我们不关心他的运行
 ****
****
10 操作系统无法预知进程的工作时间
第八章 调度:多级反馈队列
如何在对进程一无所知时做出正确策略?
本章核心问题:没有完备的知识如何调度?从历史中学习?
小点总结:
- MLFQ多级反馈队列Multi-level Feedback Queue的基本概念
- MLFQ的基本规则
- 如何改变优先级?
- 提升优先级
- S的值如何设置?
- 更好的计时方法——各优先级时间配额
- MLFQ 调优及其他问题
1 MLFQ多级反馈队列Multi-level Feedback Queue的基本概念
为满足基本概念,设定了后续的规则
- MLFQ 中有许多独立的队列,每个队列有不同的优先级
- 一个工作只能存在于一个队列中
- MLFQ 总是优先执行较高优先级的工作
- 相同优先级队列中的工作轮转RR调度
- 工作过程中动态调整优先级
2 MLFQ的基本规则
- 规则1:如果A的优先级 > B的优先级,则运行A(不运行B)
- 规则2:如果A的优先级 = B的优先级,则轮转运行A、B
3 如何改变优先级?
基本思路:
- 交互型工作运行时间短、主动放弃CPU
- 计算密集型工作一直占据CPU
- 规则3:工作进入系统时,放在最高优先级
- 假设工作是短工作,那么在优先级下降到最低前就可能已经结束,如果没结束,说明是长工作,到了最低优先级
- 规则4a:工作用完整个时间片后,降低其优先级
- 规则4b:工作过程中主动释放CPU则优先级不变
- IO密集型要求IO任务时及时启动IO,故保持较高优先级
存在的问题:
- IO密集型要求IO任务时及时启动IO,故保持较高优先级
- 若一个进程运行99%的时间片时间就主动放弃一次CPU,则会导致该进程几乎独占CPU
- 有些进程在某些阶段是IO密集型,有些阶段是CPU计算密集型
4 提升优先级
- 规则5:经过一段时间S,将系统所有的工作重新加入最高优先级队列
- 可以防止进程被“饿死”
5 S的值如何设置?
- S 设置得太高,长工作会饥饿
- 设置得太低,交互型工作又 得不到合适的 CPU 时间比例
6 更好的计时方法——各优先级时间配额
- 规则4:一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次 CPU),就降低其优先级(移入低一级队列)。
7 MLFQ 调优及其他问题
问题纷繁复杂、有时间找论文吧
第九章 调度:比例份额
确保每一个进程获得一定比例的CPU时间,而不是优化周转时间和响应时间
本章核心问题:如何按比例分配CPU
本章小点:
- 彩票数表示份额
- 随机方法的好处
- 彩票调度的简单实现
- 彩票制度的随机性导致短任务的不公平
- 如何分配彩票?
- 如何优化短任务的不公平性?步长调度
- 彩票调度的好处
总结:彩票制度新加进程、步长制度保证公平
1 彩票数表示份额
每个进程有对应的彩票数,有总的彩票数,进程彩票越多,抽到奖的概率越大
2 随机方法的好处
可以避免奇怪的边角情况
随机方法很轻量,几乎不需要记录任何状态
随即方法很快
3 彩票的机制
- 彩票分发
- 彩票转让
- 彩票通胀
4 彩票调度的简单实现
- 链表存储彩票份额
- 每次调度时,先“掷骰子”,然后遍历链表,遇到一个节点,加上该彩票数,如果大于骰子值,则选择该进程
- 链表按照彩票数递减排列时,效率高
5 彩票制度的随机性导致短任务的不公平
6 如何分配彩票?
未知?
7 如何优化短任务的不公平性?步长调度
- 步长和彩票数成反比
- 每次进程运行后,行程pass增加步长
- 当需要调度时,选择步长及行程值最小的进程
注:步长和彩票决定当下执行哪一个进程,尽可能确保了调度时按照彩票数来分配CPU时间,步长和每次CPU上进程的运行时间没关系,只是决定每次是否运行某个进程
8 彩票调度的好处
不需要全局变量
第十章 多处理器调度(高级)
浮光掠影初探多处理器调度
本章小点:
- 多核和多处理器的区别
- 什么是缓存?
1 多核和多处理器的区别
- 多核指的是拥有多个执行单元的 CPU
- 多处理器指的是有两个或者两个以上 CPU 的 CPU 系统
- 多处理器的缓存一致性问题
- 解决缓存一致性的问题
- 使用互斥原语来保证共享数据操作的准确性
- 缓存亲和性
- 单队列调度
- 亲和度机制
- 多队列调度
- Linux多处理器调度
2 什么是缓存?
缓存在计算机中的位置(如下图)
缓存是很小但很快的存储设备,通常拥有内存中最热的数据的备份。而内存很大但访问速度慢;通过将频繁访问的数据放在缓存中,系统似乎拥有有大又快的内存。
缓存是基于局部性的概念,局部性有两种,时间局部性和空间局部性。时间局部性是指当一个数据被访问后,很可能会在不久的将来被再次访问。空间局部性是指,进程访问地址为x的数据,很可能会接着访问x周围的数据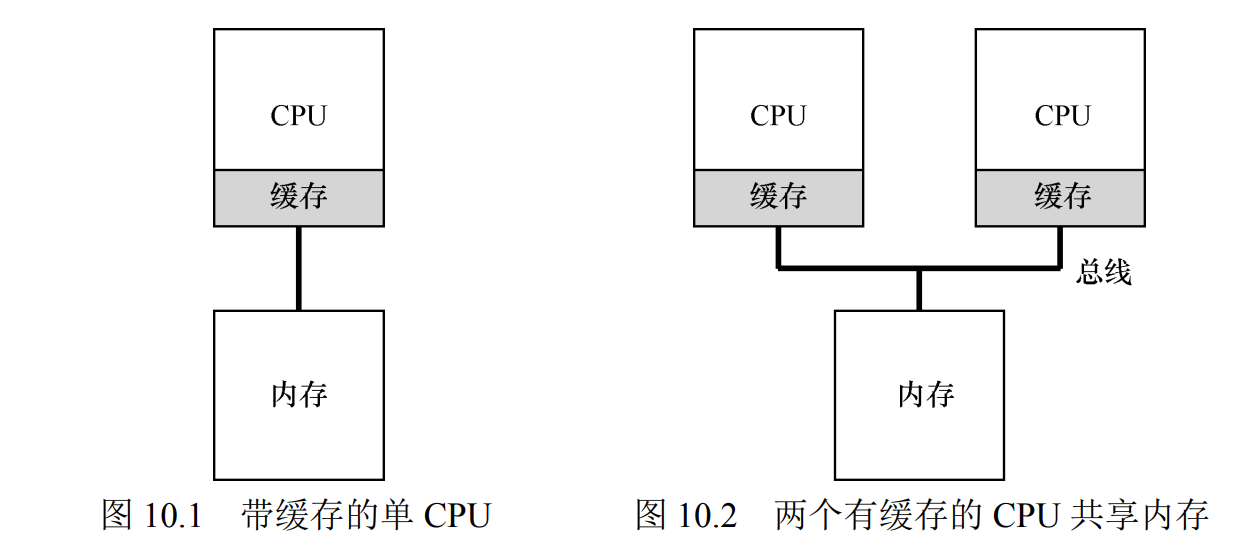
3 多处理器的缓存一致性问题
运行在CPU1上的程序从内存地址A读取数据,由于数据不在CPU1的缓存中,所以系统直接访问内存,得到值D,程序然后修改了位于地址A的值,只是在缓存中将其修改为D',这时,操作系统中止该程序的运行,将其交付给CPU2,重新读取地址A的数据,由于CPU2的缓存没有该数据,所以会直接从内存中读取,得到了旧值D,而不是正确的值D'
4 解决缓存一致性的问题
本质,请看计算机体系结构
粗看,硬件提供了这个问题的解决方案
- 通过监控内存访问,硬件可以保证获得正确的数据,保证共享内存的唯一性
- 使用总线窥探
5 使用互斥原语来保证共享数据操作的准确性
6 缓存亲和性
一个进程在切换CPU时需要重新加载缓存?这会导致效率低。所以尽可能在一个CPU执行
7 单队列调度
SQMS单队列多处理器调度Single Queue Multiprocessor Scheduling
将所有需要调度的工作放入单独的队列
缺点
- 缺乏可扩展性:加锁保证原子性,同时带来巨大的性能损耗
- 缓存亲和性低:A-B-C-D-E在队列中循环执行时,缺点如下图

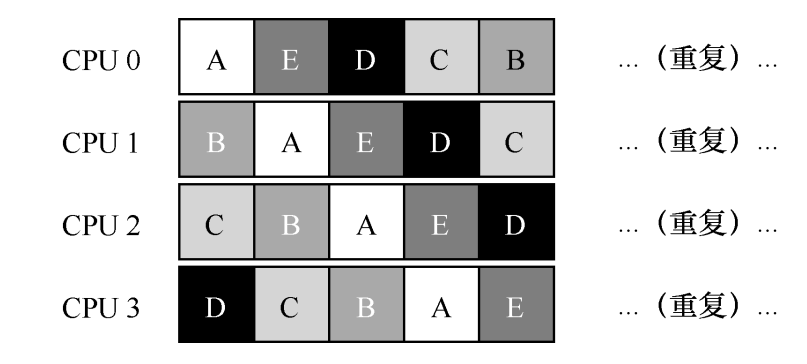
8 亲和度机制
尽可能让进程在同一个CPU上执行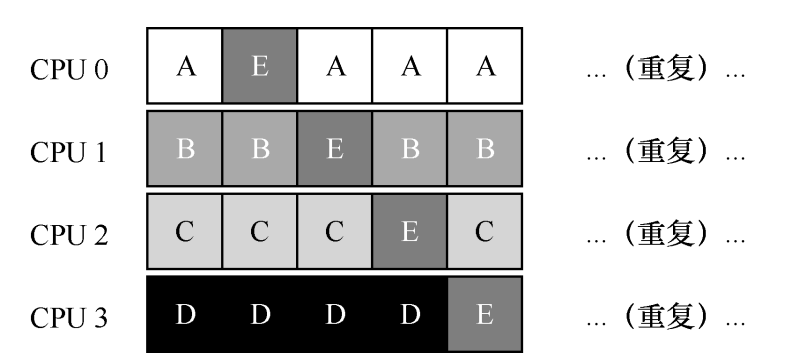
9 多队列调度
Multi-Queue Multiprocessor Scheduling MQMS
以每个CPU一个队列为例
在MQMS中
- 每个队列内部可按照轮转等不同算法
- 当新工作来到系统,系统按照随机或其他方法将其放入一个调度队列
以两个CPU为例


MQMS相比SQMS的优势
- 可扩展性
存在的问题:负载不均
如何解决?让工作移动——跨CPU迁移
10 Linux多处理器调度
- O(1)调度程序
- 完全公平调度程序(CFS)
- BF 调度程序(BFS)